My take on What We Owe The Future

Overview
What We Owe The Future (WWOTF) by Will MacAskill has recently been released with much fanfare. While I strongly agree that future people matter morally and we should act based on this, I think the book isn’t clear enough about MacAskill’s views on longtermist priorities, and to the extent it is it presents a mistaken view of the most promising longtermist interventions.
I argue that MacAskill:
- Underestimates risk of misaligned AI takeover. more
- Overestimates risk from stagnation. more
- Isn’t clear enough about longtermist priorities. more
I highlight and expand on these disagreements in part to contribute to the debate on these topics, but also make a practical recommendation.
While I like some aspects of the book, I think The Precipice is a substantially better introduction for potential longtermist direct workers, e.g. as a book given away to talented university students. For instance, I’m worried people will feel bait-and-switched if they get into EA via WWOTF then do an 80,000 Hours call or hang out around their EA university group and realize most people think AI risk is the biggest longtermist priority, many thinking this by a large margin.[1] more
What I disagree with[2]
Underestimating risk of misaligned AI takeover
Overall probability of takeover
In endnote 2.22 (p. 274), MacAskill writes [emphasis mine]:
I put that possibility [of misaligned AI takeover] at around 3 percent this century… I think most of the risk we face comes from scenarios where there is a hot or cold war between great powers.
I think a 3% chance of misaligned AI takeover this century is too low, with 90% confidence.[3] Most of the risk coming from scenarios with hot or cold great power wars may be technically true if one thinks a war between US and China is >50% likely soon which might be reasonable with a loose definition of cold war. That being said, I strongly think MacAskill’s claim about great power war gives the wrong impression of the most probable AI takeover threat models.
My credence on misaligned AI takeover is 35%[4] this century, of which not much depends on a great power war scenario.
Below I’ll explain why my best-guess credence is 35%: the biggest input is a report on power-seeking AI, but I’ll also list some other inputs then aggregate the inputs.
Power-seeking AI report
The best analysis estimating the chance of existential risk (x-risk) from misaligned AI takeover that I’m aware of is Is Power-Seeking AI an Existential Risk? by Joseph Carlsmith.[5]
Carlsmith decomposes a possible existential catastrophe from AI into 6 steps, each conditional on the previous ones:
- Timelines: By 2070, it will be possible and financially feasible to build APS-AI: systems with advanced capabilities (outperform humans at tasks important for gaining power), agentic planning (make plans then acts on them), and strategic awareness (its plans are based on models of the world good enough to overpower humans).
- Incentives: There will be strong incentives to build and deploy APS-AI.
- Alignment difficulty: It will be much harder to build APS-AI systems that don’t seek power in unintended ways, than ones that would seek power but are superficially attractive to deploy.
- High-impact failures: Some deployed APS-AI systems will seek power in unintended and high-impact ways, collectively causing >$1 trillion in damage.
- Disempowerment: Some of the power-seeking will in aggregate permanently disempower all of humanity.
- Catastrophe: The disempowerment will constitute an existential catastrophe.
I’ll first discuss my component probabilities for a catastrophe by 2100 rather than 2070[6], then discuss the implications of Carlsmith’s own assessment as well as reviewers of his report.
-
Timelines: By 2100, it will be possible and financially feasible to build APS-AI: systems with advanced capabilities (outperform humans at tasks important for gaining power), agentic planning (make plans then acts on them), and strategic awareness (its plans are based on models of the world good enough to overpower humans). 80%
- I explain this probability for Transformative AI (TAI) below. I don’t think my probability changes much between TAI and APS-AI.[7]
-
Incentives: There will be strong incentives to build and deploy APS-AI. 85%
- I think it’s very likely that APS systems will be much more useful than non-APS systems, as expanded upon in Section 3.1 of the report. It seems like so far systems that are closer to APS and more general have been more effective, and I only see reasons for this incentive gradient to become stronger over time.
-
Alignment difficulty: It will be much harder to build APS-AI systems that don’t seek power in unintended ways, than ones that would seek power but are superficially attractive to deploy. 75%
- Fundamentally, controlling an agent much more capable than yourself feels very hard to me; I like the analogy of a child having to hire an adult to be their company’s CEO described here. I don’t see much reason for hope based on the progress of existing technical alignment strategies. My current biggest hope is that we can use non-APS AIs in various ways to help automate alignment research and figure out how to align APS-AIs. But I’m not sure how much mileage we can get with this; see here for more.
-
High-impact failures: Some deployed APS-AI systems will seek power in unintended and high-impact ways, collectively causing >$1 trillion in damage. 90%
- Once misaligned APS-AI systems are being deployed, I think we’re in a pretty scary place. If at least one is deployed probably many will be deployed (if the first one doesn’t disempower us) due to correlation on how hard alignment is, and even if we’re very careful at first the systems will get smarter over time and there will be more of them; high-impact failures feel inevitable.
-
Disempowerment: Some of the power-seeking will in aggregate permanently disempower all of humanity. 80%
- Seems like a narrow “capabilities target” to get something that causes a high-impact failure but doesn’t disempower us, relative to the range of possible capabilities of AI systems. But I have some hope for a huge warning shot that wakes people up, or that killing everyone turns out to be really really hard.
-
Catastrophe: The disempowerment will constitute an existential catastrophe. 95%
- Conditional on unintentional disempowerment of humanity, it’s likely that almost all possible value in the future would be lost as there’s a large possible space of values, and most of them being optimized lead to ~value-less worlds from the perspective of human values (see also Value is Fragile). I basically agree with Carlsmith’s reasoning in the report.
This gives me a ~35% chance of existential risk from misaligned AI takeover by 2100, based on my rough personal credences.
Carlsmith, the author of the report, originally ended up with 5% risk. As of May 2022 he is up to >10%.
I’ve read all of the reviews and found the ones from Nate Soares (in particular, the sections on alignment difficulty and misalignment outcomes) and Daniel Kokotajlo to be the most compelling.[8] They have p(AI doom by 2070) at >77% and 65% respectively. Some of the points that resonated the most with me:
- By Soares: The AI may not even need to look all that superficially good, because the actors will be under various pressures to persuade themselves that things look good. Soares expects the world to look more derpy than competent, see our COVID response.
- By Soares: ‘I suspect I think that the capability band "do a trillion dollars worth of damage, but don't Kill All Humans" is narrower / harder to hit and I suspect we disagree about how much warning shots help civilization get its act together and do better next time.’
- By Kokotajlo: ‘Beware isolated demands for rigor. Imagine someone in 1960 saying “Some people thought battleships would beat carriers. Others thought that the entire war would be won from the air. Predicting this stuff is hard; we shouldn’t be confident. Therefore, we shouldn’t assign more than 90% credence to the claim that computers will be militarily useful, e.g. in weapon guidance systems or submarine sensor suites. Maybe it’ll turn out that it’s cheaper and more effective to just use humans, or bio-engineered dogs, or whatever. Or maybe there’ll be anti-computer weapons that render them useless. Who knows. The future is hard to predict.” This is what the author sounds like to me; I want to say “Battleships vs. carriers was a relatively hard prediction problem; whether computers would be militarily useful was an easy one. It’s obvious that APS systems will be powerful and useful for some important niches, just like how it was obvious in 1960 that computers would have at least a few important military applications.’ (and in general I think the whole Incentives section of Kokotajlo’s review is great)
Other inputs
A few more pieces that have informed my views:
- Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover by Cotra: I found this fairly compelling by spelling out a fairly plausible story with fairly short AI timelines and an AI takeover. In sum: an AI is trained using human feedback on diverse tasks e.g. generally doing useful things on a computer. The AI learns general skills, deceives humans during the training phase to get higher rewards than an honest strategy, then after deployment of many copies takes over humanity to either “maximize reward forever” or pursue whatever its actual goals are. I think (as does Ajeya Cotra, the author) that something close to the exact story is unlikely to play out, but I think the piece is very useful nonetheless as the xkcd linked in the post indicates.
- AGI Ruin: A List of Lethalities by Yudkowsky: While I’m more optimistic about our chances than Yudkowsky, I think the majority of the things he’s pointing at are real, non-trivial difficulties that we need to keep in mind and could easily fail to address. The rest of the 2022 MIRI Alignment discussion seems informative as well, though I haven’t had a chance to read most of it in-depth. Replies to AGI Ruin from Paul Christiano and the DeepMind alignment team are also great reads: it’s important to note how much about the situation all 3 parties agree on, despite some important disagreements.
Finally, I’ve updated some based on my experience with Samotsvety forecasters when discussing AI risk. We’ve primarily selected forecasters to invite for having good scores and leaving reasonable comments, rather than any ideological tests. When we discussed the report on power-seeking AI, I expected tons of skepticism but in fact almost all forecasters seemed to give >=5% to disempowerment by power-seeking AI by 2070, with many giving >=10%. I’m curious to see the results of Tetlock group’s x-risk forecasting tournament as well. To be clear, I don’t think we should update too much based on generalist forecasters as opposed to those who have engaged for years of their life and have good judgment; but I do think it’s a relevant data point.
[Edited to add]: I've now published Samotsvety aggregate forecasts here:
A few of the headline aggregate forecasts are:
- 25% chance of misaligned AI takeover by 2100, barring pre-APS-AI catastrophe
- 81% chance of Transformative AI (TAI) by 2100, barring pre-TAI catastrophe
- 32% chance of AGI being developed in the next 20 years
Aggregating inputs
So I end up with something like:
- A ~35% chance of misaligned AI takeover this century based on my independent impression.
- Many people who I respect are much lower, but some are substantially higher, including Kokotajlo and Soares.
I’m going to stick to 35% for now, but it’s a very tough question and I could see ending up at anywhere between 10-90% on further reflection and discussion.
Treatment of timelines
In endnote 2.22 (p. 274), MacAskill gives 30% to faster-than-exponential growth. My understanding is that this is almost all due to scenarios involving TAI, so MacAskill's credence on TAI by 2100 is approximately 30% + the 3% from AI takeover = 33%. I think 33% is too low with 85% confidence.
My credence in Transformative AI (TAI) by 2100 is ~80% barring pre-TAI catastrophe.
Some reasoning informing my view:
-
As explained here, the bio anchors report includes an evolution anchor forecasting when we would create TAI if we had to do as many computations as all animals in history combined, to copy natural selection. It finds that even under this conservative assumption, there is a 50% chance of TAI by 2100.[9] While I don’t put that much weight on the report as a whole because all individual AI forecasting methods have serious limitations, I think it’s the best self-contained AI timelines argument out there and does provide some evidence for 50% TAI by 2100 as a soft lower bound.
-
Human feedback on diverse tasks (HFDT) as described here already feels like a somewhat plausible story for TAI; while I am skeptical it will just work without many hiccups (I give ~10-15% to TAI within 10 years), 80 years is a really long time to refine techniques and scale up architecture + data.
-
AI research already is sped up by AI a little, and may soon be sped up substantially more, leading to faster progress.
-
This spreadsheet linked from this post collects “Examples of AI improving AI” including NVIDIA using AI to optimize their GPU designs and Google using AI to optimize AI accelerator chips.
-
One story that seems plausible is: language model (LM) tools are already improving the productivity of Google developers a little. We don’t appear to yet be hitting diminishing returns to better LMs: scale, data, and simple low-hanging fruit like chain-of-thought and collecting a better dataset[10] are yielding huge improvements. Therefore, we should expect LM tools to get better and better at speeding up AI research which will lead to faster progress.
-
AI research might be easy to automate relative to other tasks since humans aren’t very optimized for it by natural selection (see also Moravec’s paradox, point stolen from Ngo in MIRI conversations).
-
-
For a range of opinions on the chance of APS-AI by 2070, see here. Most reviewers are above 50%, even ones who are skeptical of large risks from misaligned AI.
-
Holden Karnofsky gave ~67% to TAI by 2100, before Ajeya Cotra (author of the bio anchors report) moved her timelines closer.
- My impression is that Karnofsky has longer timelines than almost all of the people closest to being AI forecasting “experts” (e.g. Cotra, Kokotajlo, Carlsmith) though there are selection effects here.
So overall, the picture looks to me like: 50% is a conservative soft lower bound for TAI by 2100, I have some inside view reasons to think it might be likely much sooner, and many of the most reasonable people who have thought the most about this subject tend to give at least 67%. On the other hand, I give some weight to us being very mistaken. Mashing all these intuitions together gives me a best guess of 80%, though I think I could end up at anywhere between 60% and 90% on further reflection and discussion.
Significantly shorter AI timelines dramatically increase the importance of reducing AI risk relative to other interventions[11], especially preventing stagnation as discussed below.
Treatment of alignment
The section “AI and Entrenchment” (beginning p. 83) focuses on risks from aligned AIs, and comes before “AI Takeover”. This seems like a mistake of emphasis as the risks of misalignment feel much larger, given that right now we don't know how to align an AGI.[12]
MacAskill writes on p.87:
Often the risk of AI takeover is bundled with other risks of human extinction. But this is a mistake. First, not all AI takeover scenarios would result in human extinction.
I agree this is technically true, but I think in practice it’s probably not a substantial consideration. I think with 90% confidence that the vast majority (>90%) of misaligned AI takeovers would cause extinction or would practically have the same effect, given that they would destroy humanity’s potential.
From a moral perspective AI takeover looks very different from other extinction risks… AI agents would continue civilisation… It’s an open question how good or bad such a civilisation would be… What’s at stake when navigating the transition to a world with advanced AI, then, is not whether civilisation continues but which civilisation continues.
I think it’s very likely (>=95%) that the civilisation would be bad conditional on AI misalignment, as described above (see proposition 6: Catastrophe).
Since MacAskill doesn’t give a precise credence in this section it’s hard to say with what confidence I disagree, but I’d guess ~80%.
Overestimating risk from stagnation
In Chapter 7, MacAskill discusses stagnation from a longtermist perspective. I’ll argue that he overestimates both the chance of stagnation and the expected length of stagnation.
Since I give a ~7x lower chance of stagnation and ~1.5x shorter expected length, I think MacAskill overrates extinction risk from stagnation extending the time of perils by ~10x.[13]
I then explain why this matters.
Overestimating chance of stagnation
In endnote 2.22 (p. 274), MacAskill writes [emphasis mine]:
This century, the world could take one of approximately four trajectories… I think the stagnation scenario is most likely, followed by the faster-than-exponential growth scenario… If I had to give precise credences, I’d say: 35 percent[14]
Note that stagnation is defined here as GDP growth slowing, separate from global catastrophes.[15]
Kudos to MacAskill for giving a credence here! I’ll argue that the credence is an extremely implausible overestimate. My credence in stagnation this century is 5%, and the aggregated forecast of 5 Samotsvety forecasters (one of which is me) is also 5%, with a range of 1-10%. I think MacAskill’s 35% credence is too high with 95% confidence.
I’ll explain some intuitions behind why MacAskill’s 35% credence is way too high below: AI timelines, non-AI tech, and overestimating the rate of decline in researcher productivity.
AI timelines
As discussed above, my credence on TAI by 2100 barring catastrophe is 80%, while MacAskill’s is ~33%. My TAI timelines put an upper bound of 20% on stagnation this century, so this is driving a substantial portion of the disagreement here.
However, there is some remaining disagreement from non-TAI worlds as well. MacAskill gives 35% to stagnation this century and ~33% to TAI this century, implying 35/67 = ~52% chance of stagnation in non-TAI worlds. I think MacAskill gives too much credence to stagnation in non-TAI worlds, with 75% confidence.
I give 5/20 = 25% to stagnation in non-TAI worlds; in the next 2 sections I’ll explore the reasons behind this disagreement.
Non-AI tech
It seems like there’s other tech that’s already feasible or close that could get us out of stagnation, which are mainly not applied due to taboos: in particular human cloning[16] and genetic enhancement[17]. I think if stagnation started to look likely, at least some countries would experiment with these technologies. I’d guess there would be strong incentives to do so, as any country that did would have the chance at becoming a world power.
Overestimating rate of decline in research productivity
Beginning on p. 150, MacAskill discusses two competing effects regarding whether scientific progress is getting easier or harder:
There are two competing effects. On the one hand, we “stand on the shoulders of giants”: previous discoveries can make future progress easier. The invention of the internet made researching this book, for example, much easier than it would have been in the past. On the other hand, we “pick the low-hanging fruit”: we make the easy discoveries first, so those that remain are more difficult. You can only invent the wheel once, and once you have, it’s harder to find a similarly important invention.
MacAskill then argues that “picking the low-hanging fruit” predominates, meaning past progress makes future progress harder. I agree that it almost certainly dominates but am significantly less confident on to what extent it still does in the Internet age, which leads me to expect stagnation to occur more gradually.
Qualitatively, MacAskill gives the examples of Einstein and the Large Hadron Collider:
In 1905, his “miracle year,” Albert Einstein revolutionized physics… while working as a patent clerk. Compared to Einstein’s day, progress in physics is now much harder to achieve. The Large Hadron Collider cost about $5 billion, and thousands of people were involved.
While there may be diminishing returns within physics in a somewhat similar paradigm, an important point left out here is paradigm shifts: there may very often be strong diminishing returns to research effort within a paradigm, but when a new paradigm arises many new low-hanging fruit pop up.[18] We can see this effect recently in deep learning: since the GPT-3 paper came out, many low-hanging fruit have been picked quickly such as chain-of-thought prompting and correcting language model scaling laws.
The stronger argument that MacAskill presents is quantitative. He argues on p.151 and in endnote 7.26 that since 1800, research effort has grown by at least 500x while productivity growth rates have stayed the same or declined a bit. This would mean research productivity has declined at least 500x. I roughly agree that research effort has grown at least 500x.
The key question in my mind is to what extent “effective” productivity growth rates have actually approximately stayed the same (I agree they very likely haven’t increased a corresponding 500x, but 5x-50x seems plausible), due to measurement issues. How much can we trust statistics like TFP and even GDP to capture research productivity in the Internet age? My current take is that they’re useful, but we should take them with a huge grain of salt. I have two concerns: (a) lack of capturing the most talented people’s output, and (b) lags between research productivity and impact on GDP.
First, many of the most talented people now work in sectors such as software where their output is mostly not captured by either GDP or TFP. For example, I’d predict many of the most productive people would rather give up 50% of their salary than give up internet access or even search engines (see this paper which studies this empirically but not targeted at the most productive people); but this consumer surplus is barely counted in GDP statistics.[19] MacAskill attempts to address considerations like this in endnote 7.10. I don’t find his argument that GDP was likely mismeasuring progress even more greatly before 1970 than it is now convincing but am open to having my mind changed. I’d guess that the Internet and services on top of it are a much bigger deal in terms of research productivity than e.g. the telephone, providing a bigger surplus than previous technologies.[20]
Second, there’s likely a significant lag between research productivity and impact on GDP.[21] The Internet is still relatively new, but we can see with e.g. AI research that big things seem to be on the horizon that haven’t yet made a dent in GDP.
Overestimating length of stagnation
On p.159, MacAskill suggests that the expected length of stagnation is likely over 1,000 years:
Even if you think it's 90% likely that stagnation would last only a couple of centuries and just 10 percent likely that it would last ten thousand years, then the expected length of stagnation is still over a thousand years.
I disagree. I think the expected length of stagnation is <1,000 years with 70% confidence. I’d put the expected length of stagnation at 600 years, and give <2% to a stagnation of at least 10,000 years.
In the section “How Long Would Stagnation Last” (beginning p. 156), MacAskill gives a few arguments for why stagnation might “last for centuries or even millennia”.
Getting out of stagnation requires only that one country at one point in time, is able to reboot sustained technological progress. And if there are a diversity of societies, with evolving cultures and institutional arrangements over time, then it seems likely that one will manage to restart growth… However, … to a significant extent we are already living in a global culture. If that culture develops into one that is not conducive to technological progress, that could make stagnation more persistent.
We’ve already seen the homogenising force of modern secular culture for some high-fertility religious groups… A single global culture could be especially opposed to science and technology if there were a world government.
I agree that our culture is much more globally homogeneous than it used to be; but it still feels fairly heterogeneous to me, and becoming more homogeneous seems to be strongly correlated with more transformative technologies. Additionally, one needs to think not only that society will become homogeneous but that it will stay homogeneous for millenia; I’d give this <5%, especially conditioning on stagnation having occurred which would make technologies enabling enforcement of homogeneity less powerful. This includes the possibility of strong world governments; I’m very skeptical of their likelihood or stability without transformative technologies.
A second reason why stagnation might last a long time is population decline… In this situation, the bar for an outlier culture to restart technological progress is much higher.
This point feels stronger, but I think I likely still assign less weight to it than MacAskill since persistent population decline feels more likely in worlds which are very homogenous. If the world is somewhat heterogeneous, all you need are a few remaining cultures with high fertility rates which will dominate over time. Thus this point is very correlated to the above point.
The world population could also decrease dramatically as a result of a global catastrophe… Perhaps a stagnant future is characterised by recurrent global catastrophes that repeatedly inhibit escape from stagnation.
This scenario feels the most plausible to me. But it seems like the best interventions to prevent this type of long stagnation are targeted at avoiding catastrophes or rebuilding after them (e.g. civilizational refuges), rather than trying to ensure that tech progress will persist through the catastrophes.
Why this matters
MacAskill argues that risk of stagnation is high so contributing to technological progress is good and is unsure if even speeding up AI progress would be good or bad, e.g. on p.244:
We need to ensure that the engine of technological progress keeps running.
On p.224:
I just don’t know… Is it good or bad to accelerate AI development… speeding it up could help reduce the risk of technological stagnation.
I think contributing to general tech progress is ~neutral and speeding up AI progress is bad (also related to my disagreements about AI risk).
Another implication of differences in AI and future tech timelines specifically is that it discounts the value of working on stuff aimed at very long-run effects substantially. For example, MacAskill discusses how long surface coal will last on p. 140, concluding that it will “probably last longer” than ~50-300 years depending on the region. He writes “But from a longterm point of view, we need to take these sorts of timescales seriously.”
I think AI + other tech will very likely (>90%) have changed the world so massively by then that it mostly doesn’t make much sense to think about from this sort of lens. Similarly, I put much less weight than MacAskill on the importance of increasing fertility rates (though it seems net positive).
Lack of clarity on longtermist priorities
My impression is that if someone read through this book, they would get a mistaken impression of what longtermist priorities actually are and should be. For example, as far as I remember there is little in the book that makes it clear that reducing AI and bio-risk is likely a higher priority on the margin than maintaining technological progress or fighting climate change. This is in contrast to The Precipice, which has a table summarizing the author’s estimations of the magnitude of risks.
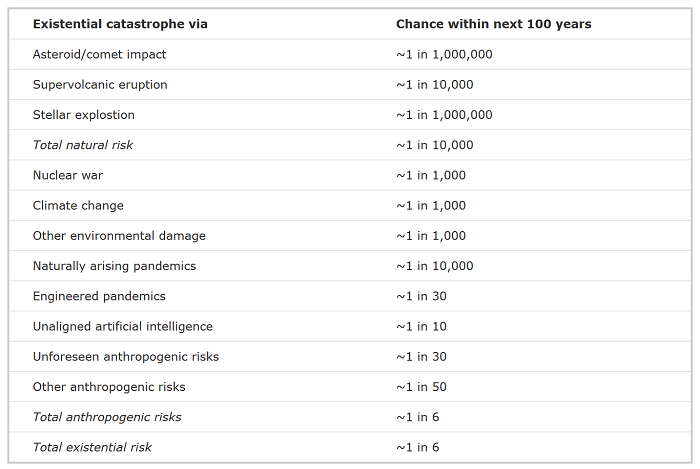{kind=link}
MacAskill at times seemed reluctant to quantify his best-guess credences, especially in the main text. His estimates for the likelihood of stagnation vs. catastrophe vs. growth scenarios as well as AI risk and biorisk are buried in the middle of endnote 2.22. There are some bio-risk estimates on p. 113, but these are citing others rather than giving MacAskill’s own view.
MacAskill doesn’t directly state his best guess credence regarding AI timelines, instead putting it in endnote 2.22 in a fairly indirect way (credence on faster-than-exponential growth, “perhaps driven by advances in artificial intelligence”); but as mentioned above this is an extremely important parameter for prioritization. He introduces the SPC framework but in few places provides numerical estimates of significance, persistence, and contingency, preferring to make qualitative arguments.
I think this will leave readers with a mistaken sense of longtermist priorities and also makes it harder to productively disagree with the book and continue the debate. For example, I realized via feedback on this draft that MacAskill’s AI timelines actually are indirectly given in endnote 2.22, but at first I missed this which made it harder to identify cruxes.
For further thoughts on the extent to which longtermist prioritization is emphasized in the book framed as a reply to MacAskill’s comments regarding his reasoning, see the appendix.
What I like
Discussing the importance of value lock-in from AI
While as described above I think the current biggest problem we have to solve is figuring out how to reliably align a powerful AI at all, I did appreciate the discussion of value lock-in possibilities even when it’s aligned. I liked the section “Building a Morally Exploratory World” (beginning p.97) and would be concerned about AI safety researchers who think of alignment more as getting the AGI to have our current values rather than something like making the AI help us figure out what our ideal values are before implementing them.
I think this has been discussed for a while among AI safety researchers, e.g. the idea of Coherent Extrapolated Volition. But it sometimes gets lost in current discussions and I think it’s a significant point in favor of AI safety researchers and policymakers being altruistically motivated.[22]
Introducing the SPC framework
In the section “A Framework for Thinking About the Future” (beginning p. 31), MacAskill introduces the SPC (Significance, Persistence, Contingency) Framework for assessing the long-term value of an action:
- Significance: What’s the average value added by bringing about a certain state of affairs?
- Persistence: How long will this state of affairs last once it has been brought about?
- Contingency: If not for the action under consideration, how briefly would the world have been in this state of affairs (if ever)?
I found the framework interesting and it seems like a fairly useful decomposition of the value of longtermist interventions, particularly ones that aren’t aimed at reducing x-risk.
Presenting an emotionally compelling case for longtermism
I personally find the idea that future people matter equally very intuitive, but I still found the case for longtermism in Chapter 1 (especially the first section of the book “The Silent Billions”) relatively emotionally compelling and have heard others also did.
I also loved the passage on page 72 about being a moral entrepreneur:
Lay was the paradigm of a moral entrepreneur: someone who thought deeply about morality, took it very seriously, was utterly willing to act in accordance with his convictions, and was regarded as an eccentric, a weirdo, for that reason. We should aspire to be weirdos like him. Others may mock you for being concerned about people who will be born in thousands of years’ time. But many at the time mocked the abolitionists. We are very far from creating the perfect society, and until then, in order to drive forward, moral progress, we need morally motivated heretics who are able to endure ridicule from those who wish to preserve the status quo.
Why I prefer The Precipice for potential longtermist direct workers
I would strongly prefer to give The Precipice rather than WWOTF as an introduction to potential longtermist direct workers. An example of a potential longtermist direct worker is a talented university student.
I’m not making strong claims about other groups like the general public or policymakers, though I’d tentatively weakly prefer The Precipice for them as well since I think it’s more accurate and we need strong reasons to sacrifice accuracy.
I prefer The Precipice because:
-
It generally seems more likely to make correct claims, especially on AI risk.
- Even though I think it still underestimates AI risk, it focuses to a larger extent on misalignment.
- While I don’t think accuracy is the only desirable quality in a book that’s someone’s intro to EA, I think it’s fairly important. And The Precipice doesn’t seem much worse on other important axes.
-
It makes the author’s view on longtermist priorities much more clear.
- Someone could read WWOTF and come out having little preference between reducing AI risk, maintaining tech progress, speeding up clean energy, etc.
- I predict ~25% of people will feel bait-and-switched if they get into EA via WWOTF then do an 80,000 Hours call or hang out around their EA university group and realize most people think AI risk is the biggest longtermist priority, many thinking this by a large margin.
-
I’d push back against a counter-argument that it’s nice to have a gentle introduction for people uncomfortable with subjective probabilities, prioritization, and AI takeover scenarios.
- Prioritization and a willingness to use numbers even when they feel arbitrary (while not taking them too seriously) are virtues close to the core of EA, that I’d want many longtermist direct workers to have.
- I’d much prefer people who are willing to take ideas that initially seem weird seriously, I think we should usually filter for these types of people when doing outreach.[23]
- [Edited to add]: I think being up front about our beliefs and prioritization mindset might be important for maintaining and improving community epistemics, which I think is an extremely important goal. See this comment for further thoughts.
-
One big difference between The Precipice and WWOTF that I’m not as sure about is the framing of reducing x-risks as interventions as opposed to trajectory changes and safeguarding civilization. I lean toward The Precipice and x-risks here but this belief isn’t very resilient.
- See the appendix for more on the likelihood of the best possible future which is one crux on whether it makes sense to primarily use the x-risk framing, though another important one is which is more intuitive/motivating to potential high-impact contributors.
Acknowledgments
Thanks to Nuño Sempere, Misha Yagudin, Alex Lawsen, Michel Justen, Max Daniel, Charlie Griffin, and others for very helpful feedback. Thanks to Tolga Bilge, Greg Justice, Jonathan Mann, and Aaron Ho for forecasts on stagnation likelihood. Thanks to a few others for conversations that helped me refine my views on the book.
The claims in this piece ultimately represent my views and not necessarily those of anyone else listed above unless explicitly stated otherwise.
Comment on this post on the EA Forum.
Appendix
Defining confidence in unresolvable claims
Throughout the review I argue for several unresolvable (i.e. we’ll never find out the correct answer), directional claims like:
MacAskill arrives at [credence/estimate] X for claim Y, and I think this is too [high/low] with Z% confidence
At first I wasn’t going to do this because this type of confidence is often poorly defined and misinterpreted, but I decided it was worth it to propose a definition and go ahead and use as many made-up numbers as possible for transparency.
I define Z% confidence that X is too [high/low] as meaning: I have a credence of Z% that an ideal reasoning process instantiated in today’s world working with our current evidence would end up with a best-guess estimate for claim Y that is [lower/higher] than X. The exact instantiation of an ideal reasoning process is open to interpretation/debate, but I’ll gesture at something like “take some combination of many (e.g. 100) very reasonable people (e.g. generalist forecasters with a great track record) and many domain experts who have a scout mindset, freeze time for everyone else, then give them a very large amount of time (e.g. 1000 years) to figure out their aggregated best guess”. The people doing the reasoning can only deliberate about current evidence rather than acquire new evidence (by e.g. doing object-level work on AI to better understand AI timelines).
A property of making directional claims like this is that MacAskill always has 50% confidence in the claim I’m making, since I’m claiming that his best-guess estimate is too high/low. (Edit: this actually isn't right, see this comment for why)
Thoughts on likelihood of the best possible future
In endnote 2.22, MacAskill writes [emphasis mine]:
I think that the expected value of the continued survival of civilisation is positive, but it’s very far from the best possible future. If I had to put numbers on it, I’d say that the expected value of civilisation’s continuation is less than 1 percent that of the best possible future (where “best possible” means “best we could feasibly achieve”).
The biggest difference between us regards how good we expect the future to be. Toby thinks that, if we avoid major catastrophe over the next few centuries, then we have something like a fifty-fifty chance of achieving something close to the best possible future. I think the odds are much lower. Primarily for this reason, I prefer not to use the language of “existential risk” (for reasons I spell out in Appendix 1) and prefer to distinguish between improving the future conditional on survival (“trajectory changes,” like avoiding bad value lock-in) and extending the lifespan of civilisation (“civilisational safeguarding,” like reducing extinction risks).
Despite generally agreeing with The Precipice much more than WWOTF, I’m less sure who I agree with on this point and therefore whether the x-risk framing is better. I lean toward Ord and would give a ~15% chance of achieving the best possible future if we avoid catastrophe, but this credence has low resilience.
Thoughts on MacAskill’s recent posts/comments related to the framing of the book
AMA post and responses
MacAskill wrote a post announcing WWOTF and doing an AMA. In the post, he writes:
The primary aim is to introduce the idea of longtermism to a broader audience, but I think there are hopefully some things that’ll be of interest to engaged EAs, too: there are deep dives on moral contingency, value lock-in, civilisation collapse and recovery, stagnation, population ethics and the value of the future. It also tries to bring a historical perspective to bear on these issues more often than is usual in the standard discussions.
I think there are some things of interest to engaged EAs, but as I’ve argued I think the book isn’t a good introduction for potential highly engaged EAs. I understand the appeal in gentle introductions (I got in through Doing Good Better), but I think it’s 90% likely I would have also gotten very interested if I had gone straight to The Precipice and so would most highly engaged longtermist EAs.
MacAskill wrote in some comments:
Highlighting one aspect of it: I agree that being generally silent on prioritization across recommended actions is a way in which WWOTF lacks EA-helpfulness that it could have had. This is just a matter of time and space constraints. For chapters 2-7, my main aim was to respond to someone who says, “You’re saying we can improve the long-term future?!? That’s crazy!”, where my response is “Agree it seems crazy, but actually we can improve the long-term future in lots of ways!”
I wasn’t aiming to respond to someone who says “Ok, I buy that we can improve the long-term future. But what’s top-priority?” That would take another few books to do (e.g. one book alone on the magnitude of AI x-risk), and would also be less “timeless”, as our priorities might well change over the coming years.
It would be a very different book if the audience had been EAs. There would have been a lot more on prioritisation (see response to Berger thread above), a lot more numbers and back-of-the-envelope calculations, a lot more on AI, a lot more deep philosophy arguments, and generally more of a willingness to engage in more speculative arguments. I’d have had more of the philosophy essay “In this chapter I argue that..” style, and I’d have put less effort into “bringing the ideas to life” via metaphors and case studies. Chapters 8 and 9, on population ethics and on the value of the future, are the chapters that are most similar to how I’d have written the book if it were written for EAs - but even so, they’d still have been pretty different.
I don’t think it’s obvious, but I’m still pretty skeptical of this sort of reasoning. What do we expect the people who are very skeptical about prioritizing and putting numbers on things to actually do to have a large impact? And I’m still concerned about bait-and-switches as mentioned above; even Doing Good Better talked heavily about prioritization, while WWOTF might leave people feeling weird when they actually join the community and realize that there are strong prioritization opinions not discussed in the book.
It seems important for EA’s community health that we can be relatively clear about our beliefs and what they imply. To the extent we’re not, I think we’ll potentially turn off some of the most talented potential contributors. If I try to put myself in the shoes of someone getting into EA through WWOTF then realizing that in fact there is a ton of emphasis in the longtermist movement on a relatively small portion of actions described in the book, I think I’d be somewhat turned off. I don’t think this is worth potentially appealing a bit more to the general public.
Response to Scott Alexander
Similarly, MacAskill wrote a forum comment in response to Scott Alexander which might provide some insight into the framing of the book. Some reactions to the theme I found most interesting:
message testing from Rethink suggests that longtermism and existential risk have similarly-good reactions from the educated general public, and AI risk doesn’t do great.
A lot of people just hate the idea of AI risk (cf Twitter), thinking of it as a tech bro issue, or doomsday cultism. This has been coming up in the twitter response to WWOTF, too, even though existential risk from AI takeover is only a small part of the book. And this is important, because I’d think that the median view among people working on x-risk (including me) is that the large majority of the risk comes from AI rather than bio or other sources. So “holy shit, x-risk” is mainly, “holy shit, AI risk”.
I’m skeptical that we should give much weight to message testing with the “educated general public” or the reaction of people on Twitter, at least when writing for an audience including lots of potential direct work contributors. I think impact is heavy-tailed and we should target talented people with a scout mindset who are willing to take weird ideas seriously.
And as mentioned above, it seems healthy to have a community that’s open about our beliefs including the weird ones, and especially about the cause area that is considered by many (including perhaps MacAskill?) to be the top longtermist priority. Being less open about weird beliefs may turn off some of the people with the most potential.
Thoughts on the balance of positive and negative value in current lives
In the section “How Many People Have Positive Wellbeing” (beginning p.195), MacAskill uses self-reports to attempt to answer whether “the world is better than nothing for the human beings alive today.”
First, I’m very skeptical of self-reports as evidence here and think that it’s extremely hard for us to answer this question given our current understanding. When I think about some good experiences I had and some bad experiences I had and whether I’d prefer both of them to non-existence, I mostly think “idk? seems really hard to weigh these against each other.” I’m skeptical that others really have much more clarity here.[24]
Second, I think even given the results of the self-reports it’s puzzling to me that on p. 201, MacAskill concludes that if he were given an option to live a randomly chosen life today he would. The most convincing evidence to me that he describes is a survey that asked people whether they’d skip parts of their day if they could (discussed on p. 198). MacAskill writes:
Taking both duration and intensity into account, the negative experiences were only bad enough to cancel out 58 percent of people’s positive experiences… the right conclusion is actually more pessimistic… participants in these studies mainly lived in the United States or in other countries with comparatively high income levels and levels of happiness
MacAskill then goes on to describe a survey of people in both India and the United States whether their whole life has been net good. Due to the difficulty weighing experiences I described above and rosy retrospection biases, I put very little weight on this follow-up study. If we mainly focus on the “skipping” study, I think the result should make us somewhat pessimistic about the overall value of the current world. In addition to the consideration MacAskill brought up, the study likely didn’t include many examples of extreme suffering, which seem quite bad compared to the range of positive experiences accessible to us today even through a classical utilitarian lens.
I feel like I basically have no idea, but if I had to guess I’d say ~40% of current human lives are net-negative, and the world as a whole is worse than nothing for humans alive today because extreme suffering is pretty bad compared to currently achievable positive states. This does not mean that I think this trend will continue into the future; I think the future has positive EV due to AI + future tech.
Notes
Edited in for clarity: my concern is not that people won't toe the "party line" of longtermism and think AI is the most important; I'm very in favor of people forming their own views and encouraging new people to share their perspectives. My primary concern here is the effects of the lack of transparency in WWOTF about MacAskill's views on longtermist prioritization (and to the extent people interpret the book as representing longtermism in some sense, lack of clarity on the movement's opinions). ↩︎
In this section I do my best to give my all-things-considered beliefs (belief after updating on what other people believe), rather than or in addition to my (explicitly flagged when given) independent impressions. That being said, I think it’s pretty hard to separate out independent impressions vs. all-things-considered beliefs on complex topics when you’re weighing many forms of evidence, and beliefs are formed over a long period of time. When initially writing this review I thought MacAskill was attempting to give his all-things-considered credences in WWOTF, but from discussing with reviewers it seems MacAskill is giving something closer to his independent impression when possible, or something like: “independent impressions and [MacAskill is] confused about how to update in light of peer disagreement". Though note that MacAskill shares a similar sentiment about it being difficult to separate between these, and his credences should likely be interpreted as somewhere in between all-things-considered beliefs and independent impressions. To the extent MacAskill isn’t trying to take into account peer disagreement, he isn’t necessarily trying to predict what an ideal reasoning process would output as described in the appendix. ↩︎
See this appendix section for how I’m defining confidence in directional, unresolvable claims. ↩︎
Formerly had 40% in this post, corrected to 35% due to correcting the mistake of failing to multiply 6 probabilities together correctly. ↩︎
I strongly recommend reading it or, if you’re short on time, watching this presentation by the author. ↩︎
I’m intending to think more about this and flesh these out further in a post, hopefully within 1-2 months. ↩︎
The 80% below was assuming no catastrophes; I’ll also assume no other catastrophes here for simplicity, and because I think people often do this when estimating non-AI risks so it seems good to be consistent. ↩︎
MacAskill mentions in a forum comment he liked Ben Garfinkel’s review of the report. I personally didn’t find it that persuasive and generally agreed with Carlsmith’s counterpoints more than Garfinkel’s points, but it might be a good source for those who want the best arguments that Carlsmith is overestimating rather than underestimating AI risk. ↩︎
See also A concern about the “evolutionary anchor” of Ajeya Cotra’s report on AI timelines for some pushback and discussion. ↩︎
See also AI Forecasting: One Year In: “Specifically, progress on ML benchmarks happened significantly faster than forecasters expected. But forecasters predicted faster progress than I did personally, and my sense is that I expect somewhat faster progress than the median ML researcher does.” ↩︎
See also this comment by Carl Shulman: “There are very expensive interventions that are financially constrained… so that e.g. twice the probability of AGI in the next 10 years justifies spending twice as much for a given result by doubling the chance the result gets to be applied” ↩︎
I think there’s some chance aligning AGIs turns out to not be that hard (e.g. if we just tell it to do good stuff and not to do bad stuff plus somewhat intensive adversarial training + red-teaming, it mostly works) but it’s <50%. ↩︎
In earlier drafts I gave a 10x lower chance of stagnation and a 2.5x shorter expected length for 25x less weight overall, but after some discussion I now think I was underselling the evidence in the book for decline in researcher productivity (I previously thought it perhaps hadn’t declined at all, and now just disagree about the degree) as well as the arguments for long expected length of stagnation. While I still place significantly less weight on stagnation than MacAskill, I’m less skeptical than I initially was (and differing AI timelines are doing about half of the work on my skepticism). ↩︎
Another place where this is brought up is p.162: “Even if stagnation has only a one-in-three chance of occurring…” I’m not sure where the jump from a best guess of 35% to a lower reasonable bound of 33% comes from. ↩︎
Though I’m a bit confused as the definition in the endnote seems to conflict with this quote on p.159, also discussed below: “Perhaps a stagnant future is characterized by recurrent global catastrophes that repeatedly inhibit escape from stagnation” ↩︎
This is mentioned in the book on p. 156. See endnote 7.50: ‘Mu-Ming Poo, said in 2018 that “technically, there is no barrier to human cloning”’ ↩︎
See Predicting Polygenic Selection for IQ by Beck ↩︎
This point is inspired by this section of a rebuttal essay to Bloom et al.'s "Are Ideas Getting Harder to Find". ↩︎
This point taken from this section of a rebuttal to Bloom et al. ↩︎
A reviewer mentioned The Rise and Fall of American Growth: The U.S. Standard of Living Since the Civil War as a further reference defending the argument in endnote 7.10. I didn’t get a chance to look into the book. ↩︎
I’m particularly unsure about this point, feel free to tear it to shreds if it’s invalid. ↩︎
As opposed to e.g. wanting to avoid their own death. I think this is fine to have as a supplementary motivation if it helps increase productivity and grasp the urgency of the problem, but on reflection the motivation being altruistic seems good to me. That being said, if someone is really talented and not that altruistic but wants to work on AI safety I’d likely still be excited about them working on it, given how neglected the problem is. ↩︎
To be clear, I’m excited about people who aren’t quickly convinced by weird ideas like a substantial probability of AI takeover in the next 50 years! But I’d prefer people who engage critically and curiously with weird ideas rather than disengage. ↩︎
On why I think this objection is reasonable even though I don’t really provide a great alternative:
Relying on self-reports to a significant extent feels like streetlight fallacy to me. I don't think we should update much based on self-reports, especially the type that involves asking people if their whole life has been good or bad rather than looking moment to moment. I don't think I need to provide a better alternative besides intuition / philosophical reasoning to make this claim.
MacAskill does caveat self-reports some but I think the vibe is much more authoritative than I'd prefer, and the caveats much less strongly worded. I'd go for the vibe of "we have no idea wtf is going on here, here's the best empirical evidence we have but DON'T TAKE IT SERIOUSLY AT ALL IT'S REALLY SHITTY" ↩︎