Prioritizing x-risks may require caring about future people

Introduction
Several recent popular posts (here, here, and here) have made the case that existential risks (x-risks) should be introduced without appealing to longtermism or the idea that future people have moral value. They tend to argue or imply that x-risks would still be justified as a priority without caring about future people. I felt intuitively skeptical of this claim[1] and decided to stress-test it.
In this post, I:
- Argue that prioritizing x-risks over near-term interventions and global catastrophic risks may require caring about future people. More
- Disambiguate connotations of “longtermism”, and suggest a strategy for introducing the priority of existential risks. More
- Review and respond to previous articles which mostly argued that longtermism wasn’t necessary for prioritizing existential risks. More
Prioritizing x-risks may require caring about future people
I’ll do some rough analyses on the value of x-risk interventions vs. (a) near-term interventions, such as global health and animal welfare and (b) global catastrophic risk (GCR) interventions, such as reducing risk of nuclear war. I assume a lack of caring about future people to test whether it’s necessary for prioritizing x-risk above alternatives. My goal is to do a quick first pass, which I’d love for others to build on / challenge / improve!
I find that without taking into account future people, x-risk interventions are approximately[2] as cost-effective as near-term and GCR interventions. Therefore, strongly prioritizing x-risks may require caring about future people; otherwise, it depends on non-obvious claims about the tractability of x-risk reduction and the moral weights of animals.
| Intervention | Rough estimated cost-effectiveness, current lives only ($/human-life-equivalent-saved) |
| General x-risk prevention (funding bar) | $125 to $1,250 |
| AI x-risk prevention | $375 |
| Animal welfare | $450 |
| Bio x-risk prevention | $1,000 |
| Nuclear war prevention | $1,250 |
| GiveWell-style global health (e.g. bednet distribution) | $4,500 |
Estimating the value of x-risk interventions
This paper estimates that $250B would reduce biorisk by 1%. Taking Ord’s estimate of 3% biorisk this century and a population of ~8 billion, we get: $250B / (8B * .01 * .03) = $104,167/life saved via biorisk interventions. The paper calls this a conservative estimate, so a more optimistic one might be 1-2 more OOMs as effective at ~$10,000 to ~$1,000 / life saved; let’s take the optimistic end of $1,000 / life saved as a rough best guess, since work on bio x-risk likely also reduces the likelihood of deaths from below-existential pandemics and these seem substantially more likely than the most severe ones.
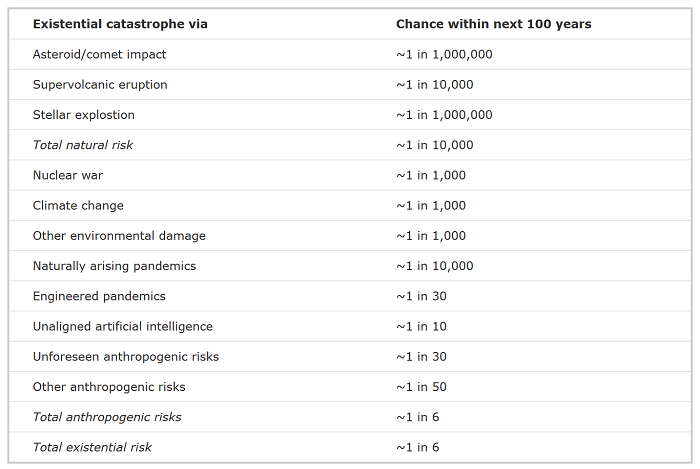{kind=link}
For AI risk, 80,000 Hours estimated several years ago that another $100M/yr (for how long? let’s say 30 years) can reduce AI risk by 1%[3][4]; unclear if this percentage is absolute or relative, relative seems more reasonable to me. Let’s again defer to Ord and assume 10% total AI risk. This gives: ($100M * 30) / (8B * .01 * .1) = $375 / life saved.
On the funding side, Linch has ideated a .01% Fund which would aim to reduce x-risks by .01% for $100M-$1B. This implies a cost-effectiveness of ($100M to $1B) / (8B * .0001) = $125 to 1,250 / life saved.
Comparing to near-term interventions
GiveWell estimates it costs $4,500 to save a life through global health interventions.
This post estimates that animal welfare interventions may be ~10x more effective, implying $450 / human life-equivalent, though this is an especially rough number.[5]
Comparing to GCR interventions
Less obviously than near-term interventions, a potential issue with not caring about future people is over-prioritizing global catastrophic risks (that might kill a substantial percentage of people but likely not destroy all future value) relative to existential risks. I’ll just consider nuclear war here as it’s the most likely non-bio GCR that I’m aware of.
80,000 Hours estimates a 10-85% chance of nuclear war in the next 100 years; let’s say 40%. As estimated by Luisa Rodriguez, full-blown nuclear war would on average kill 5 billion people but usually not lead to existential catastrophe. I’m not aware of numerical estimates of the tractability of nuclear risk: if we assume it’s the same tractability as biorisk above ($25B to reduce 1% of the risk), we get: $25B / (5B * .01 * .4) = $1,250 / life saved.
Disambiguating connotations of “longtermism”
While caring about future people might be necessary for the case for x-risks to go through, longtermism is still a confusing term. Let’s disambiguate between 2 connotations of “longtermism”:
- A focus on influencing events far in the future.
- A focus on the long-term impact of influencing (often near-medium term) events.
The word longtermism naturally evokes thoughts of (1): visions of schemes intended to influence events in 100 years time in convoluted ways. But what longtermists actually care about is (2): the long-term effects of events like existential catastrophes, even if the event itself (such as AI takeover) may be only 10-20 years away! Picturing (1) leads to objections regarding the unpredictability of events in the far future, when oftentimes longtermists are intervening on risks or risk factors expected in the near-medium term.
The subtle difference between (1) and (2) is why it sounds so weird when “longtermists” assert that AGI is coming soon so we should discount worries about climate effects 100 years out, and why some are compelled to assert that “AI safety is not longtermist”. As argued above, I think AI safety likely requires some level of caring about future people to be strongly prioritized[6]; but I think the term longtermism has a real branding problem in that it evokes thoughts of (1) much more easily than (2).
This leaves longtermists with a conundrum: the word “longtermism” evokes the wrong idea in a confusing way, but caring about future people might be necessary to make prioritization arguments go through. I’d be interested to hear others’ suggestions on how to deal with this when introducing the argument for working on x-risks, but I’ll offer a rough suggestion:
- Introduce the idea of working on existential or catastrophic risks before bringing up the word “longtermism”.
- Be clear that many of the risks are near-medium term, but part of the reason we prioritize them strongly is that if the risks are avoided humanity could create a long future.
- Use analogies to things people already care about because of their effect on future humans, e.g. climate change.[7]
Reviewing previous articles
I’ll briefly review the arguments in previous related articles and discussion, most of which argued that longtermism was unnecessary for prioritizing existential risks.
"Long-Termism" vs. "Existential Risk"
Regardless of whether these statements [...about future people mattering equally] are true, or whether you could eventually convince someone of them, they're not the most efficient way to make people concerned about something which will also, in the short term, kill them and everyone they know.
I agree that longtermism has this branding problem and it is likely not best to argue for future people mattering equally before discussing existential risks.
A 1/1 million chance of preventing apocalypse is worth 7,000 lives, which takes $30 million with GiveWell style charities. But I don't think long-termists are actually asking for $30 million to make the apocalypse 0.0001% less likely - both because we can't reliably calculate numbers that low, and because if you had $30 million you could probably do much better than 0.0001%. So I'm skeptical that problems like this are likely to come up in real life.
I think the claim that “if you had $30 million you could probably do much better than 0.0001%” is non-obvious. $30 million for a 0.0001% reduction is as cost-effective as $3 billion for a 0.01% reduction, which is only 3x off from the target effectiveness range of the .01% Fund discussed above. This seems well within the range of estimation error, rather than something you can “probably do much better than”.
I also think the claim that “we can't reliably calculate numbers that low” is very suspect as a justification; I agree that we can’t estimate low percentage existential risk impacts with much precision, but there must be some actions we’d take that our best guess estimate impact on existential risk is 0.0001% (and substantially lower); for example, a single day of work for an average AI safety researcher. It’s not obvious to me that our best guess estimate for a marginal $30 million poured into AI safety risk reduction should be >0.0001%, despite us not being able to estimate it precisely.
Other articles
- Simplify EA Pitches to "Holy Shit, X-Risk"
- This argues for >=1% AI risk and >=.1% biorisk being enough to justify working on them without longtermism, but doesn’t do any math on the tractability of reducing risks or a numerical comparison to other options.
- My Most Likely Reason to Die Young is AI X-Risk
- This argues that it’s possible to care a lot about AI safety based on it affecting yourself, your loved ones, other people alive today, etc. but doesn’t do a comparison to other possible causes.
- Carl Shulman on the common-sense case for existential risk work and its practical implications
- This argues that x-risk spending can pass a US government cost-benefit test based on willingness-to-pay to save American lives. The argument is cool in its own right but as EAs prioritizing time/money we should compare against the best possible opportunities to do good anywhere in the world, not base our threshold on the US government's willingness-to-pay.
- Alyssa Vance’s tweet about whether the longtermism debate is academic
- And Howie Lempel responding, saying he thinks he would work on global poverty or animal welfare if he knew the world was ending in 1,000 years
- Howie’s response is interesting to me, as it implies a fairly pessimistic assessment of tractability of x-risks given that 1,000 years would shift the calculations presented here by over an OOM (>10 generations).
- (Edited to add: Howie clarifies "I wouldn't put too much weight on my tweet saying I think I probably wouldn't be working on x-risk if I knew the world would end in 1,000 years and I don't think my (wild) guess at the tractability of x-risk mitigation is particularly pessimistic." with additional thoughts)
- antimonyanthony’s shortform argues longtermism isn’t redundant, making some similar points to the ones I’ve made in this post, and an additional one about the suffering-focused perspective leading to further divergence.
- “Arguments for the tractability of reducing those risks, sufficient to outweigh the nearterm good done by focusing on global human health or animal welfare, seem lacking in the arguments I’ve seen for prioritizing extinction risk reduction on non-longtermist grounds.”
- “But as far as I’ve seen, there haven’t been compelling cost-effectiveness estimates suggesting that the marginal dollar or work-hour invested in alignment is competitive with GiveWell charities or interventions against factory farming, from a purely neartermist perspective.”
- “Not all longtermist cause areas are risks that would befall currently existing beings… for those who are downside-focused, there simply isn’t this convenient convergence between near- and long-term interventions.”
Acknowledgments
Thanks to Neel Nanda, Nuño Sempere, and Misha Yagudin for feedback.
Comment on this post on the EA Forum.
It feels like suspicious convergence to me: Care about future people equally to current people? Work on X. Don’t care about future people at all? Work on X anyway! ↩︎
(Edited to add this footnote) Here, I mean within 1-2 OOMs by "approximately" due to the low resilience/robustness of many of the cost-effectiveness estimates (while 1-2 OOMs difference would be a huge deal for more resilient/robust estimates). ↩︎
I’ve sometimes seen estimates from people I respect working on AI risk that estimate much higher tractability than the 80,000 Hours article and myself (if anything, I’d lean more pessimistic than 80k); I tend to take these with a grain of salt and understand that high estimates of the tractability of one’s own work might help for maintaining motivation, sanity, etc. Plus of course there are selection effects here. ↩︎
There’s a wide range of effectiveness within AI risk interventions: e.g. the effectiveness of “slam dunk” cases like funding ARC seems much higher than the last/marginal AI risk reducing dollar. Though this could also be true of some alternative near-term strategies, e.g. charity entrepreneurship! ↩︎
It’s very sensitive to moral weights between species. I’d love to hear from people who have done more in-depth comparisons here! ↩︎
One more concern I have is that caring about only present people feels “incompletely relative”, similar to how Parfit argued self-interest theory is incompletely relative in Reasons and Persons. If you don’t care about future people, why care equally about distant people? And indeed I have heard some arguments about focusing on AI safety to protect yourself / your family / your community etc., e.g. in this post. These arguments feel even more mistaken to me; if one actually only cared about themselves or their family / small community, it would very likely make sense to optimize for enjoyment which is unlikely to look like hunkering down and solving AI alignment. I concede that this motivation could be useful a la a dark art of rationality, but one should tread very carefully with incoherent justifications. ↩︎
See also Common-sense cases where "hypothetical future people" matter. ↩︎